Każda aplikacja niezależnie czy działa w chmurze czy lokalnie potrzebuje jakiegoś miejsca na przechowywanie danych.
W tym artykule chciałbym poświęcić trochę czasu na temat projektowania naszego miejsca na dane jakim jest Table Storage, wzorców projektowania jakie są dostępne (bądź rekomendowane przez Microsoft).
Jest to pierwsza część serii artykułów poświęconych Table Storage, oraz tematyki projektowania naszego storage tak aby działał efektywnie.
A więc przejdźmy do konkretów.
Table storage automatycznie indeksuje kolumny PartitionKey i RowKey dzięki temu wyszukiwanie po nich jest szybkie i efektywne. Co w sytuacji gdy musimy wyszukać nasze dane używając innych parametrów? Tutaj z pomocą przychodzą nam wzorce projektowe dla Table Storage.
Przejdźmy przez kilka z nich i zobaczmy jakie mają cechy, kiedy je stosować, oraz jakie mają wady.
Intra-partition secondary index pattern
Pierwszy wzorzec, który swoje działanie opiera o zapisywanie w jednej tabeli wielu duplikowanych danych ale z różnym RowKey. Wszystkie dane są przechowywane w obrębie tego samego PartitionKey. Dlaczego zapisujemy dane w jednej tabeli i tym samym PartitionKey?
Ponieważ w razie aktualizacji danych możemy skorzystać z ETG, czyli Entity Group Transactions. O którym napiszemy sobie kiedy indziej ;).
Rozwiązuje on problem pobierania danych po różnych kluczach i w systemach potrzebujących danych posortowanych w różny sposób.
Problem do rozwiązania?
Chcemy pobrać dane o naszych produktach w kategorii, oraz dane produktów powiązane z konkretnym magazynem.
Dodatkowo chcemy to zrobić szybko tak żeby operator nie musiał długo czekać na wynik operacji.
Przykład

Nasze dany będą trzymane w obrębie jednej tabeli z różnym podziałem na PartitionKey i RowKey.
Jaki mogą pojawić się problemy
- Musimy wziąć pod uwagę, że ilość naszych danych będzie rosła w dużym tempie.
- Musimy pamiętać o aktualizacji wielu różnych encji.
- Musimy wziąć pod uwagę skalowalność pojedynczego PartitionKey.
- Każda encja musi mieć unikalny RowKey.
- Musimy oszacować koszt wykorzystania takiej architektury. Tutaj z pomocą przychodzi fakt, że ATS jest jednym z najtańszych storage w Azure.
Inter-partition secondary index pattern
Drugi wzorzec rozwiązuje problem przechowywania powiązanych ze sobą danych z różnym RowKey, oraz w tej samej bądź różnych tabelach.
Rozwiązuje on problem pobierania danych po różnych kluczach i w systemach potrzebujących danych posortowanych w różny sposób, oraz rozwiązuje problem skalowania PartitionKey.
Problem do rozwiązania?
Chcemy pobrać dane o naszych produktach w kategorii, oraz produkty danego typu powiązane z konkretnym magazynem.
Dodatkowo chcemy to zrobić szybko tak żeby operator nie musiał długo czekać na wynik operacji.
Przykład

Nasze dany będą trzymane w obrębie jednej tabeli z różnym podziałem na PartitionKey i RowKey.
Jaki mogą pojawić się problemy
- Musimy wziąć pod uwagę, że ilość naszych danych będzie rosła w dużym tempie.
- Musimy pamiętać o aktualizacji wielu różnych encji.
- Musimy wziąć pod uwagę skalowalność pojedynczego PartitionKey.
- Każda encja musi mieć unikalny RowKey.
- Musimy oszacować koszt wykorzystania takiej architektury. Tutaj z pomocą przychodzi fakt, że ATS jest jednym z najtańszych storage w Azure.
Eventually consistent transactions pattern
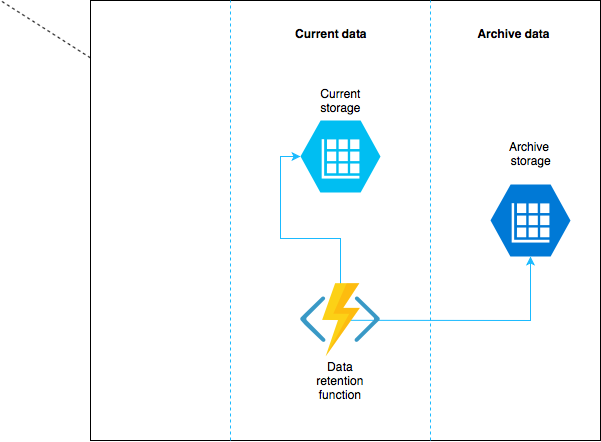
Czasami mamy sytuację kiedy nasze dane są rozproszone po różnych tabelach naszej instancji Table Storage lub nawet między różnymi Table Storage. Typowym przypadkiem użycia jest tzw. Data Retention Policy gdzie nasze dane po pewnym czasie powinny zostać zarchiwizowane.
Problem do rozwiązania?
Archiwizacja danych w Table Storage. Chcemy przenieść do archiwum część danych o produktach, które nie są już w sprzedaży.
Przykład

{kind=link}
Jaki mogą pojawić się problemy
- Głównym problemem jaki może się pojawić w takim rozwiązaniu jest próba odczytu danych z archiwum kiedy jeszcze się one tam nie znalazły.
Podsumowanie
Jak widzicie projektowanie naszego storage nie zawsze jest proste i wielokrotnie trzeba przemyśleć problemy związane ze skalowaniem, oraz kosztami. Całe szczęście przychodzą nam z pomocą tzw. Table design patterns.
W kolejnej części zajmiemy się kolejnymi wzorcami, oraz będziemy dalej zgłębiać zagadnienia związane z projektowaniem naszego storage.
Photo by Shahadat Rahman on Unsplash
 Maciej Gos
Maciej Gos
真诚赞赏,手留余香
使用微信扫描二维码完成支付

comments powered by Disqus